SQL הוא כלי עבודה מרכזי עבור רוב האנליסטים וגם עבורי. ברמה המקצועית, תמיד משמח אותי לגלות איזו פונקציה חדשה שלא הכרתי אשר יכולה לחסוך לי זמן יקר. בפוסט המצורף החלטתי לרכז במקום אחד את כל אותם ״טריקים״ קטנים בSQL שאספתי עם השנים, עם דגש על דברים שימושיים שבאמת משמשים אותי ביום יום. על אף שניסיתי לא ללכת למובן מאליו, מניח שחלק מהנושאים שידונו בפוסט ידועים יותר וחלקם ידועים פחות – אבל כל המציל נפש אחת כאילו הציל עולם ומלואו.
מטבע הדברים, קיים שוני בהתאם לסביבת ה-SQL בה האנליסט משתמש. המאמר יעסוק ב Big Query של גוגל שזו המערכת בה אני עושה שימוש. אם אתם משתמשים בסוג אחר של SQL סיכוי סביר שהפונקציות שאציין פה קיימות גם במערכות שלכם אבל בשמות אחרים (אם כי לא בטוח).
קיצור מקלדת
באופן כללי, אפשר לדעת הרבה לגבי הרמה של אנליסט בלי לקרוא שורת קוד אחת שלו ורק מלהתבונן בכמה מסודרת השאילתה שהוא כותב והאופן בו הוא משתמש במקלדת. יש אין ספור קיצורי מקלדת למערכות Mac ו-Windows אבל למי שכותב שאילתות, הקיצור החשוב ביותר שהוא צריך להכיר הוא:
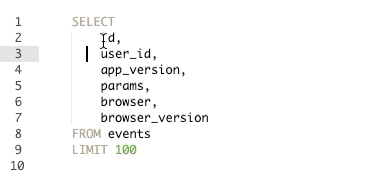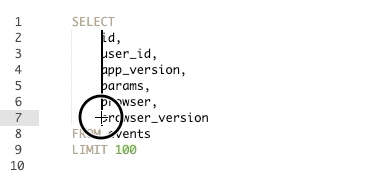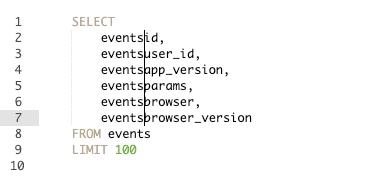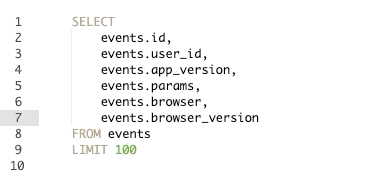

שימוש בקיצור הנ״ל יאריך את הסמן של הטקסט מה שיאפשר לכם לכתוב במספר שורות במקביל. שימוש נכון ביכולת הזו מאפשר לתקן שאילתות או לייצר שורות חדשות במהירות כפולה ומכופלת. על מנת לנצל את היכולת הזו עד תום רצוי לשלב עם עוד שני קיצורים:
Option+Shift+right/left Arrow Keys– שמאפשר להזיז את סמן הטקסט ימינה או שמאלה ברמת המילה (במקום ברמת האות).
Command+Shift+right/left Arrow Keys– שמאפשר להזיז את סמן הטסקסט לסוף או תחילת השורה.
מעבר לזה, להלן רשימת קיצורים נוספת מהתיעוד של ביג קוורי (שבאופן פושע לא כוללת את השימוש בסמן שהראתי):

סינטקסט
Select * Except
אם יצא לכם לכתוב שאילתה בה רציתם למשוך כמעט את כל העמודות של טבלה מסוימת, אז הקוד הבא הוא בשבילכם ודי מסביר את עצמו.
Select * Except(age)
from users“If” instead of “Case”
בעוד אני מניח שכולכם מכירים את הסינטקסט של Case When, ביג קוורי מאפשר להשתמש גם בפונקציית IF שצריכה להיות מוכרת לכל מי שמשתמש באקסל, ולטעמי נוחה ואלגנטית יותר לשימוש במקרה שהתנאי הלוגי הוא בינארי.
--case
Case When country='US' Then counntry else 'ROW' end is_usa
--if
if(country='US',counntry,'ROW')is_usa“Using” instead of “On”
חיבור טבלאות באמצעות Join הוא פעולה בסיסית שחוזרת על עצמה הרבה במהלך כתיבת שאילתות. במקרים רבים נחבר טבלאות כאשר העמודה המחברת נושאת את אותו שם. במקרים כאלו אני אוהב להשתמש בסינטקסט של using שגם חוסך במלל וגם מאפשר להשתמש בשם העמודה בשאילתה עצמה ללא צורך בציון הטבלה ממנה היא הגיעה (מה שגם יכול לגרום בעיות במקרים מסויימים, להבין יותר מומלץ לקרוא את התיעוד של גוגל)

פונקציות אגרגטיביות
Group By All
הרכש החדש של ביג קוורי שהצטרף אליה ממש בחודשים האחרונים ומאפשר להפטר מהסיטנטקסט הנוראי של group by 1,2,3,4,5 ולהחליף אותו ב group by all. שימו לב לתיעוד המצורף של גוגל, השימוש ביכולת הזו כן גורר עמו כמה נקודות שצריך לתת עליהן את הדעת.
Array_AGG
לרוב פונקציות אגרגטיביות מחזירות משתנים נומינלים שבאים לבדוק כמות או להחזיר ממוצע. שימוש בArray_agg יאפשר לנו לייצר שורות מסוג Array של משתנים מספריים אך גם משתני טקסט (על איך להשתמש נכון בarray בתוך ביג קוורי אולי אקדיש פוסט נפרד) ובעצם ״לכווץ״ מספר שורות לשורה אחת. על מנת לטייב באופן יותר מדוייק את המשתנים שנרצה בתוך הרשימה נשתמש בפקודות: Distinct, Ignore Nulls, Order By & Limit
על מנת להוריד את הדברים לקרקע נשתמש מעתה והלאה בטבלה הדמיונית הבאה שמתארת רכישות של שני לקוחות בתוך אתר E-Commence לאורך מספר ביקורים:

הקוד הנ״ל מראה איך באמצעות שאילתה אגרגטיבית ניתן, מלבד לאסוף מידע נומינלי, גם לרכז את כל הרכישות של לקוח עבור כל לקוח:

לאלו שנרתעים משימוש ברשימות ניתן להשתמש גם String_AGG על מנת לייצר עמודת טקסט שתכלול את כל הקניות של הלקוח. בשימוש בפונקציה זו נצטרך לציין איך להפריד בין כל פריט טקסט (במקרה שלי בחרתי להשתמש בפסיק).

MAX_by/MIN_by
לבטח כל הקוראים מכירים את פונקציות Max ו Min אבל האחיות הפחות מוכרות שלהן שימושיות לא פחות. בעזרת פונקציות אלו נוכל להביא ערך מסויים בטבלה על בסיס הmin/max של עמודה אחרת. או בהקשר של הדוגמא בה השתמשנו מקודם- נוכל לדעת מה הייתה הרכישה של לקוח בביקור האחרון/ראשון שלו בחנות. החסרון שאני מוצא בפונקציה הזו היא שהיא לא יודעת להתעלם מnulls. לשם כך הוספתי דרך להתגבר על הבעיה שמשתמשת בפונקציה שהכרנו בסעיף הקודם.

CountIf
פונקציה נחמדה שמוכרת מאקסל וקיימת גם בביג קוורי, ועם זאת, ברוב הפעמים שיצא לי לעבור על קוד של אנליסטים אני רואה אותם משתמשים בשילוב של count(case when) שהוא אמנם נכון, אבל פחות אלגנטי.

Approximate Aggregate Functions
מדובר בקטגוריה של מספר פונקציות אשר כשמן כן הן, *הערכה* לגבי החישוב המבוקש בשאילתות אגרגטיביות. ההצדקה להשתמש בהן היא כאשר בידנו דאטה בייס גדול ונרצה לחסוך משאבי חישוב. לרוב אני משתמש בפונקציות הנ״ל כאשר אני כותב שאילתה אגרגטיבית ואני רוצה לחשב חציון (או כל אחוזון אחרי). כידוע, אין פונקצית חציון ייעודית עבור פונקציות אגרגטיביות (בניגוד, למשל, לחישוב ממוצע) והאלטרנטיבה של לחשב חציון דרך פונקציית חלון דורשת גם הרבה מלל וגם הרבה כוח חישוב. במקרים כאלה ניתן לפנות לפונקציה APPROX_QUANTILES באופן הבא
SELECT APPROX_QUANTILES(x, 100)[OFFSET(90)] AS percentile_90
FROM UNNEST([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) AS x;
/*---------------*
| percentile_90 |
+---------------+
| 9 |
*---------------*/זה השלב שהקורא בוודאי ישאל ״עד כמה לא מדוייק החישוב״- על כך אין לי תשובה והדבר ידרוש לצלול למעמקי הקוד של גוגל. כן אציין שבהשוואות שעשיתי בין תוצאות של פונקציית הApproximat וחישוב חציון ״קלאסי״ דרך פונקציית חלון- התוצאות יצאו זהות למדי.
Corr
בפונקציה אגרגטיבית נשתמש לרוב כדי לסדר ולנקות דאטה, פחות לנתח אותו. אבל לעתים נחמד לעשות גם אנליזה זריזה ופונקציה שיכול לעזור בזה היא פונקציית corr שתחזיר לנו את המתאם בין שני ווקטורים לפי מתאם פירסון
אחלה כתבה! ברור, שימושי ומאוד מסודר… למדתי כמה דברים חדשים!